如何评价谷歌最新发布的Gemini 2.5 pro模型?
发布时间:
2025-04-10 13:21
阅读量:
6
似乎没人说啥呀,那就只能一个评价了:差强人意,勉勉强强吧。不是它不行,是市场已经麻木了,实现不了对前三的超越,就只能是这个情况。
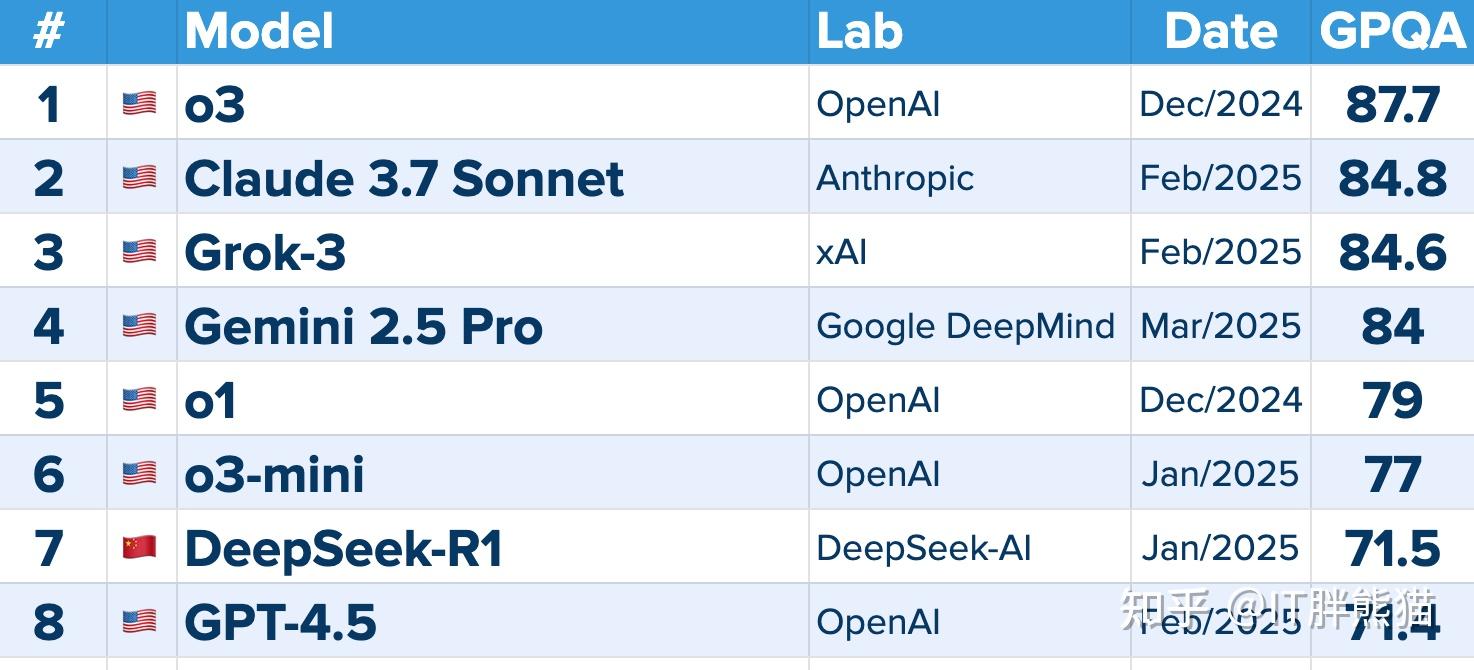
GPQA(Graduate-Level Google-Proof Q&A Benchmark)是一个用于评估高级问答系统的基准数据集。该项目旨在提供一个具有挑战性的问答数据集,以测试和提升AI模型的问答能力。GPQA数据集包含复杂的问题和答案,适合研究生级别的学术研究和工业应用。
不过也有对它表扬的,它确实做智力测验比较擅长,看下这个:
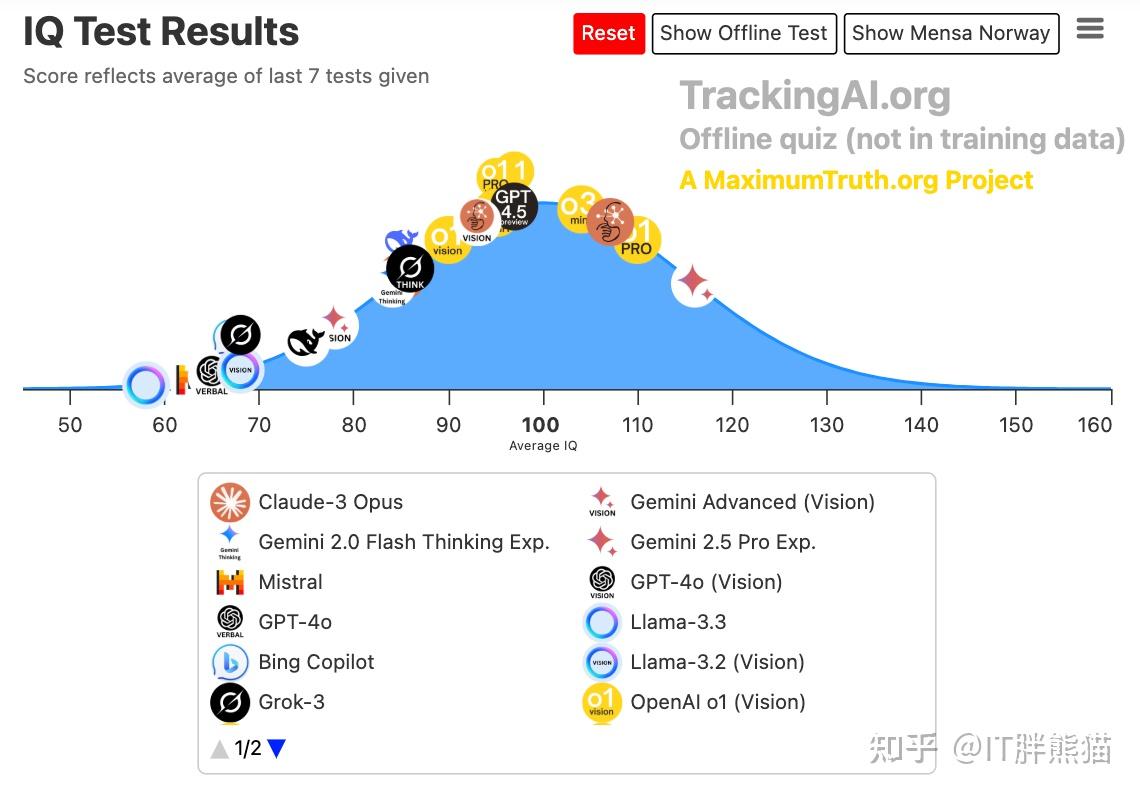
TrackingAI的测试方法比较行测化,用的是门萨智力测试题,类似下面这种的,感觉大模型也是要考公的,这个确实可以,小鲸鱼表示伤心啊。
但是OpenAI的o1也被拉过去测试过结果测得它的智商高达 120,远远超过了其他所有的大模型。具体来说,o1 在 35 个智商问题中答对了 25 个,远远高于大多数人类的表现,现在Gemini终于实现了碾压。
不过本人看来,智商测试是一种狭隘的衡量标准,要想真正评估人工智能进化,不是通过门萨测试,而是考察它们对于细微差别、背景和人类复杂性的理解,而这些是智商测试无法量化的,而且大模型这么强,还是不如一些高智商人类的,比如什么10岁小女孩智商高达162什么的。所以,对于Gemini 2.5的表现怎么说呢,勉勉强强,就那样吧。
END